强化学习落地,详解自动驾驶决策模型的训练方法
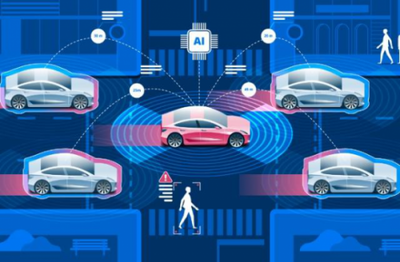
强化学习在自动驾驶领域的落地,为决策模型的训练提供了创新且高效的方法。随着汽车智能化的飞速发展,自动驾驶决策模型的精准性和可靠性愈发关键。强化学习通过智能体与环境的交互,不断优化决策策略,以适应复杂多变的道路场景。在这个过程中,如何构建合适的环境模型、设计有效的奖励机制以及优化智能体的学习算法,成为了训练自动驾驶决策模型的核心要点。
构建准确的环境模型是基础。自动驾驶面临的环境复杂多样,包括动态的其他车辆、行人以及静态的道路设施等。为了让智能体能够在这样的环境中做出合理决策,需要精确地模拟各种场景。这涉及到对交通规则、车辆动力学以及传感器数据的深入理解和建模。通过收集大量真实世界的驾驶数据,并进行标注和预处理,可以构建起一个包含丰富信息的环境模型。这个模型不仅要能够准确反映当前的路况,还要能够预测未来一段时间内环境的变化趋势。例如,通过对前车速度、加速度等信息的分析,预测其可能的行驶轨迹,从而为智能体的决策提供依据。

设计合理的奖励机制是驱动智能体学习的关键。奖励机制直接影响着智能体的行为选择,它需要根据自动驾驶的目标进行精心设计。一个好的奖励机制应该能够引导智能体做出安全、高效、舒适的驾驶决策。比如,对于安全驾驶,可以设置避免碰撞、遵守交通规则等奖励;对于高效驾驶,可以根据行驶速度、路线规划等因素给予奖励;对于舒适驾驶,可以考虑平稳加速、减速以及避免急刹车等情况给予奖励。为了平衡不同目标之间的关系,还需要对奖励进行加权处理。例如,在某些情况下,安全可能是首要考虑因素,此时安全相关的奖励权重可以适当提高。通过不断调整奖励机制,让智能体在与环境的交互中逐渐学习到最优的决策策略。
优化智能体的学习算法是提高训练效率和效果的保障。强化学习中有多种学习算法可供选择,如深度 Q 网络(DQN)、深度确定性策略梯度(DDPG)等。不同的算法适用于不同的场景和问题。在自动驾驶决策模型的训练中,需要根据具体情况选择合适的算法,并对其进行优化。例如,对于 DQN 算法,可以通过改进网络结构、引入经验回放机制等方式提高算法的稳定性和收敛速度。对于 DDPG 算法,可以采用双 Q 网络、目标网络软更新等技术来提升算法的性能。还可以结合多智能体强化学习等方法,考虑车辆之间的协同决策,进一步优化自动驾驶决策模型。
强化学习在自动驾驶决策模型的训练中具有巨大的潜力。通过构建准确的环境模型、设计合理的奖励机制以及优化智能体的学习算法,可以训练出高效、可靠的自动驾驶决策模型。要实现真正安全、智能的自动驾驶,还需要不断地进行研究和实践,解决诸如模型的可解释性、应对极端情况等诸多挑战。相信随着技术的不断进步,强化学习将在自动驾驶领域发挥越来越重要的作用,为人们带来更加便捷、安全的出行体验。