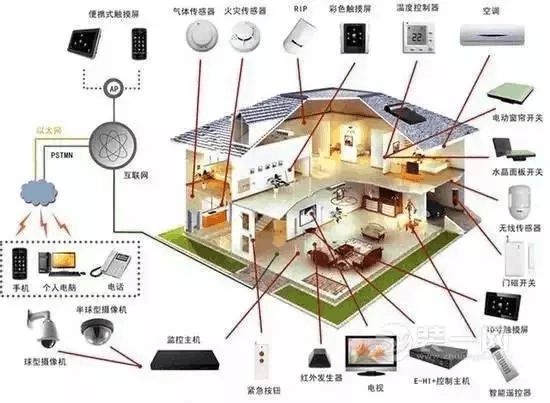
除了kettle还有哪些?全网最全的10大热门数据集成工具大盘点!
除了kettle还有哪些?全网最全的10大热门数据集成工具大盘点!
(1)拥有丰富的预构建组件库:覆盖数据抽取、转换、加载等全流程,能帮助开发人员快速搭建数据集成流程,大幅节省开发时间。
(2)支持多平台和多数据源集成:无论是企业本地系统还是云端应用,均可轻松对接。
(3)提供可视化开发环境:通过拖拽和配置组件即可完成复杂数据集成任务,降低操作门槛。
(4)具备强大的社区支持:开发者可在社区中获取各类资源与帮助。
2. 缺点
配置相对复杂除了kettle还有哪些?全网最全的10大热门数据集成工具大盘点!,需要一定技术基础才能熟练使用,对小型项目或技术要求较低的用户不够友好。 虽然有社区支持,但针对复杂问题可能无法获得及时、专业的技术支持。
3. 使用场景
适用于大型企业的数据集成和数据治理项目,尤其在跨国企业或多元化业务企业中,能整合不同地区、不同业务系统的数据,发挥多数据源集成和强大数据处理能力;同时可用于数据质量监控、元数据管理等数据治理工作,确保数据合规性与一致性。

三、. 优点
(1)具备强大的性能优化能力:可优化数据处理流程,提升数据处理速度与效率,在大规模数据处理中表现突出。
(2)提供丰富的安全机制:能保障数据集成和管理过程中的安全性与保密性,适合金融、医疗等对数据安全要求高的行业。
(3)可扩展性和兼容性良好:能与ERP、CRM等各类企业级应用和系统集成,实现数据无缝流动。
2. 缺点
属于商业软件,许可证费用较高,对小型企业或预算有限的项目可能造成经济压力。学习曲线较陡,需要专业培训才能熟练掌握。操作和维护相对复杂,需专业技术人员负责管理。
3. 使用场景
适用于对数据处理性能、安全性和可扩展性要求较高的大型企业及项目,例如金融行业的风险管理、医疗行业的电子病历管理等场景,可满足大量敏感数据的处理需求,并保障数据准确性与安全性。

四、. 优点
(1)功能强大:由IBM推出,可靠性高,具备高度可定制性,可根据企业特定需求进行定制开发,满足不同业务场景的数据处理要求。
(2)支持并行处理:在大规模数据处理时能充分利用多核处理器和分布式计算资源,提升处理效率。
(3)集成性良好:与IBM其他产品(如数据库、数据仓库等)集成性良好,可为企业提供一站式数据解决方案。
2. 缺点
作为IBM商业软件,许可证费用和维护成本较高。学习难度较大,需专业技术人员操作和维护。操作界面相对复杂,初学者需要较多时间熟悉。
3. 使用场景
适用于大型企业及对数据处理性能和定制化要求较高的项目,例如金融行业的大数据分析、电信行业的客户行为分析等场景,能有效处理大规模、复杂的数据。

五、 Data (ODI)1. 优点

与数据库集成性极佳,对使用数据库的企业而言数据清洗用到什么工具,可实现高效的数据集成。提供可视化开发环境,通过图形化界面方便设计数据集成流程。支持多种数据源,不仅能集成数据库,还可与其他数据库和系统对接。
2. 缺点
主要依赖生态系统,对非环境的支持较弱。许可证费用较高,对小型企业或非用户而言成本较高。
3. 使用场景
适用于使用数据库的企业的数据集成项目,例如在企业数据仓库建设、数据迁移等场景中,可借助与数据库的集成优势实现高效数据集成。

六、. 优点
作为自助式数据准备和分析工具,具有简单易用的特点,界面直观,业务人员无需编写代码,通过拖拽和配置即可完成数据清洗、转换、分析等任务,大幅提升工作效率。
2. 缺点
处理大规模数据时性能有限,超大规模数据处理需依赖更强的计算资源和分布式处理能力。功能集中在数据准备和分析,对数据集成和数据治理的支持较弱。
3. 使用场景
适用于业务人员主导的数据分析场景,例如市场营销分析、销售业绩分析等,业务人员可快速准备和分析数据,为业务决策提供支持。

七、 NiFi1. 优点
(1)强大的数据流管控:以可视化的数据流为核心,支持数据从采集、处理到传输的全链路管理,可灵活实现数据路由、过滤、转换等操作,适配复杂的业务流程。
(2)高可用性与弹性扩展:采用分布式集群架构,具备自动容错和负载均衡机制,能根据数据流量动态调整资源,保障系统在高并发场景下稳定运行。
(3)数据溯源与监控:提供详细的数据流日志和监控指标,可追踪数据的流转路径和处理状态,便于问题排查和性能优化。
2. 缺点
(1)资源消耗较高:运行过程中对服务器的内存和CPU占用较大,尤其是在处理大规模数据时数据清洗用到什么工具,可能需要更高配置的硬件支持。
(2)学习门槛较高:虽然界面可视化,但深入理解其底层原理、复杂数据流设计及自定义处理器开发需要一定的技术积累。
3. 使用场景
(1)物联网数据处理:适用于收集各类物联网设备(如传感器、智能终端)产生的实时数据,经过清洗、转换后传输至数据平台,例如智慧交通中的车辆轨迹数据整合。
(2)跨系统数据同步:可实现企业内部多个业务系统(如ERP、CRM、OA)之间的数据实时同步,确保各系统数据一致性,支持业务协同。

八、AWS Glue1. 优点
(1)全托管云服务:基于AWS云平台构建,无需用户部署和维护服务器数据清洗用到什么工具,极大降低了运维成本,开发者可专注于数据集成逻辑的设计。
(2)智能数据目录:能自动扫描和识别数据源中的元数据,构建统一的数据目录,方便用户快速检索和理解数据。

(3)按需计费模式:按照实际计算资源使用量收费,避免资源闲置浪费,适合数据处理量波动较大的场景(如电商大促期间的数据峰值处理)。
2. 缺点
(1)云平台依赖性强:若企业数据分布在多朵云或混合云环境中,与非AWS平台的集成复杂度较高,可能增加额外的适配成本。
(2)自定义转换能力有限:对于高度复杂的业务逻辑转换,内置功能支持不足,需要依赖脚本或外部工具辅助,灵活性稍弱。
3. 使用场景
(1)云端数据仓库构建:将AWS上分散的结构化、半结构化数据(如S3中的日志文件、RDS中的业务数据)抽取转换后加载到数据仓库,为数据分析提供统一数据源。
(2)数据湖治理:对AWS S3数据湖中的数据进行清洗、标准化和分类管理,提升数据湖的可用性和数据质量。

九、 SQL (SSIS)1. 优点
(1)与SQL 生态无缝集成:作为SQL 的原生组件,与SQL 数据库、 、 等产品协同性极佳,可直接调用数据库资源除了kettle还有哪些?全网最全的10大热门数据集成工具大盘点!,提升数据处理效率。
(2)丰富的内置组件:提供大量预定义的任务(如文件操作、FTP传输、邮件发送)和转换组件(如数据合并、拆分、排序、聚合),覆盖大部分常规数据集成场景,减少开发工作量。
2. 缺点
跨平台支持不足,主要运行在操作系统上,对Linux、Unix等平台的支持有限,在多平台混合架构的企业中应用受限。在处理TB级以上超大规模数据时,单节点性能表现一般,需要额外配置分布式架构或结合其他工具优化。
3. 使用场景
适合以SQL 为核心数据库的企业,整合内部业务系统(如财务系统、销售系统)数据,实现数据统一管理。

十、Azure Data (ADF)1. 优点
(1)低代码/无代码开发:提供可视化的拖拽式界面,业务人员和开发人员均可快速构建数据管道,无需深入编写代码,降低技术门槛。
(2)强大的调度与监控能力:支持灵活的任务调度(如按时间、事件触发),并提供实时监控面板,可追踪数据管道的运行状态、性能指标和错误信息,便于运维管理。
2. 缺点
对Azure生态依赖明显,虽然支持混合云,但与Azure服务(如Azure 、Azure Data Lake)的集成效果最优,若主要使用非Azure产品,可能存在功能适配问题。
3. 使用场景
帮助企业整合本地数据中心和Azure云端的数据,如将本地ERP系统数据同步至Azure 进行分析。连接、 365等SaaS应用,抽取业务数据与企业内部数据合并分析,支撑客户关系管理、市场营销决策等场景。

总结

数据集成工具的选择需综合考量技术栈适配性、业务场景复杂度及成本投入。从轻量级可视化工具(如)到企业级平台(如、),再到云原生服务(如AWS Glue、Azure Data ),不同方案各有侧重。建议结合自身数据规模、实时性要求及团队技术能力进行深度评估,以构建高效可靠的数据管道,驱动业务价值落地。